Видео со смартфона позволяют получить реалистичную трехмерную реконструкцию лица
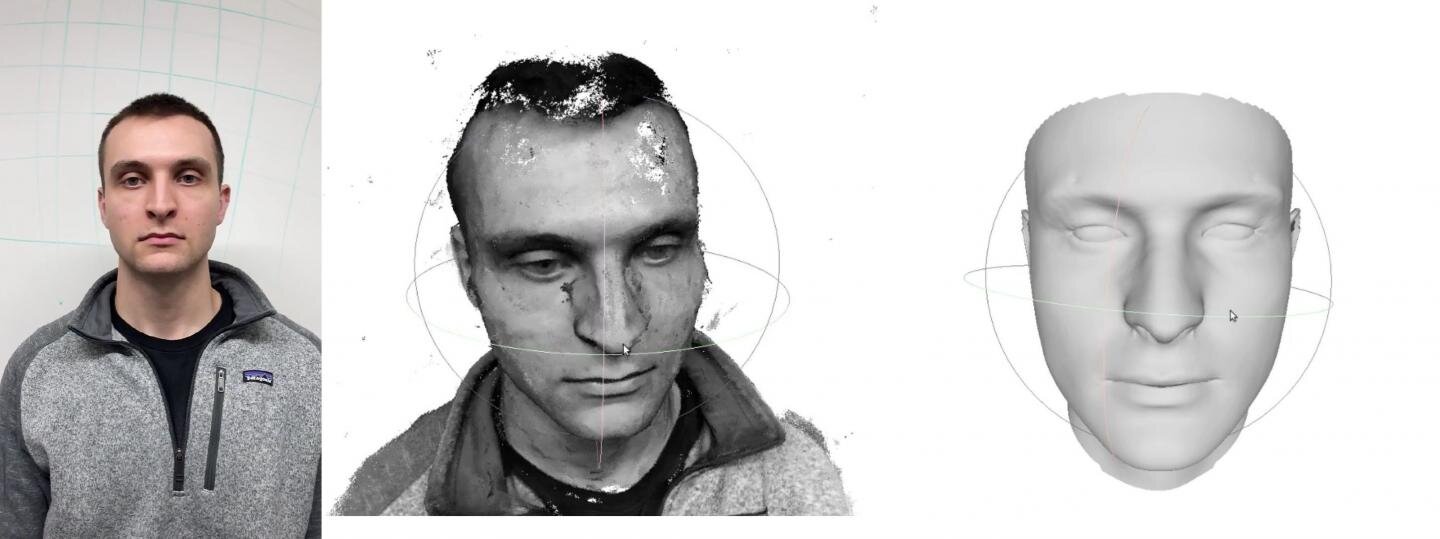
Как правило, для создания точной трехмерной реконструкции чьего-то лица, которая реалистична и не выглядит жуткой, требуется дорогостоящее оборудование и опыт. Теперь исследователи из Университета Карнеги-Меллона совершили подвиг, используя видео, записанное на обычном смартфоне.
Использование смартфона для съемки непрерывного видео на передней и боковых частях лица создает плотное облако данных. Двухступенчатый процесс, разработанный Институтом робототехники CMU, использует эти данные с помощью алгоритмов глубокого обучения для создания цифровой реконструкции лица. Эксперименты команды показывают, что их метод может достигать точности до миллиметра, опережая другие процессы на основе камеры.
Цифровое лицо может быть использовано для создания аватара для игр, виртуальной или дополненной реальности, а также для анимации, биометрической идентификации и даже медицинских процедур. Точная трехмерная визуализация лица также может быть полезна при создании индивидуальных хирургических масок или респираторов.
“Построение трехмерной реконструкции лица было открытой проблемой в компьютерном зрении и графике, потому что люди очень чувствительны к внешнему виду лица”, – сказал Саймон Люси, профессор-исследователь в Институте робототехники. “Даже незначительные аномалии в реконструкциях могут сделать конечный результат нереальным”.
Лазерные сканеры, структурированный свет и многокамерные студийные установки могут производить высокоточное сканирование лица, но эти специализированные датчики непомерно дороги для большинства применений. Однако недавно разработанный CMU метод требует только смартфон.
Метод, разработанный Люси совместно со студентами магистратуры Шубхамом Агравалом и Ануджем Пахуджа, был представлен в начале марта на зимней конференции IEEE по применению компьютерного зрения (WACV) в Сноумасс, штат Колорадо. Начинается съемка 15-20 секунд видео. В этом случае исследователи использовали iPhone X в режиме замедленной съемки.
“Высокая частота кадров замедленного движения является одним из ключевых элементов для нашего метода, потому что он генерирует плотное облако точек”, – сказала Люси.
Затем исследователи используют общепринятую технику, называемую визуальной одновременной локализацией и картированием (SLAM). Visual SLAM триангулирует точки на поверхности, чтобы вычислить ее форму, и в то же время использует эту информацию для определения положения камеры. Это создает начальную геометрию грани, но отсутствующие данные оставляют пробелы в модели.
На втором этапе этого процесса исследователи работают, чтобы заполнить эти пробелы, сначала используя алгоритмы глубокого обучения. Однако оно используется ограниченным образом: оно идентифицирует профиль человека и такие ориентиры, как уши, глаза и нос. Классические методы компьютерного зрения затем используются для заполнения пробелов.
“Глубокое обучение – это мощный инструмент, который мы используем каждый день”, – сказала Люси. “Но глубокое обучение имеет тенденцию запоминать решения, что противодействует усилиям, включающим различение деталей лица. Если вы используете эти алгоритмы просто для нахождения ориентиров, вы можете использовать классические методы, чтобы заполнить пропуски намного легче”.
Метод не обязательно быстрый, на эксперимент ушло 30-40 минут времени обработки. Но весь процесс можно выполнить на смартфоне.
По словам Люси, в дополнение к реконструкции лица, методы команды CMU могут также использоваться для захвата геометрии практически любого объекта. Цифровая реконструкция этих объектов затем может быть включена в анимацию или, возможно, передана через Интернет на сайты, где объекты могут быть продублированы с помощью 3D-принтеров.
Разместить у себя на сайте или блоге:
На любом форуме в своем сообщении:













